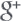Propuesta de un nuevo sistema de QA para conseguir traducciones excelentes

Mis críticas a estos programas son:
- Un 80% de los errores no son errores sino falsos positivos y elementos que se marcan como «ignore» por irrelevantes y, por tanto, alargan los plazos de entrega y hacen menos rentable la traducción por un consumo excesivo de tiempo;
- Su programación responde a correspondencias biunívocas (una palabra = una palabra) y no permiten, por tanto, los sinónimos;
- En todo caso los errores que señalan son de nivel básico (pueden señalarte, por ejemplo, falsos amigos que una persona que lleva traduciendo 10 años conoce de sobra) por lo que el nivel de calidad que buscan es de mínimos y no de máximos;
- La repetición abusiva de ciertas palabras y de estructuras puede llevar a penalizaciones de SEO (de páginas web, etc.) por «keyword stuffing». Adicionalmente, cualquiera que sea el tipo de texto (un informe, una demanda, unas cuentas anuales…) no resulta ameno para el lector un texto en el que hay demasiada repetición (el lector se aburre); finalmente la poca riqueza semántica también dará la impresión de textos artríticos, repetitivos y poco creativos por lo que no resultan adecuados para la mayoría de las industrias creativas (medios, marketing, etc.) y tampoco para textos de presentaciones de empresas.
Nuevo sistema de QA, Problema cognitivo:
Existe en la QA realizada por un robot un problema cognitivo. Cuando los humanos redactamos frases, lo hacemos pensando en el interlocutor (proceso cognitivo) siempre con el receptor de la comunicación en mente. Por tanto, existen problemas cuando el receptor es un robot y además un robot que pensamos que es molesto y estúpido. En este proceso cognitivo, el interlocutor no puede ser una máquina que va a revisar el texto porque en esa relación de comunicación se distorsiona la traducción para adaptarla a las preferencias del robot (para que no proteste o se le genere ruido), no siendo el robot el destinatario final de la comunicación. Por eso, para nosotros no funciona la QA al uso, ya que altera las bases cognitivas de la comunicación.
¿Qué programa se debería hacer, entonces, para conseguir una traducción de calidad de máximo nivel?
He reflexionado sobre el proceso de calidad de máximo nivel y este artículo describe – concretamente – cómo se podría programar una máquina revisora de máxima calidad en la traducción.
Se parte, sin embargo, de los siguientes supuestos:
- Ha realizado la traducción un experto traductor y ha hecho ya comprobaciones normales sobre términos, falsos amigos, cuestiones ortográficas;
- Se ha realizado un PROOF 1 (puede ser con la propia máquina de QA) o por una persona no experta que realizaría lo que se llama una «revisión de integridad»: que no falta nada, que los números son correctos, etc.
- La fase a la que corresponde esta QA es de PROOF 2 o de postedición de una traducción mediocre, más pegada al original y más literal para convertirla en una traducción EXCELENTE.
Nuevo sistema de QA
FASES DE LA TRADUCCIÓN Y POSTEDICIÓN AVANZADA:
- Traducción – realizada por una persona experta;
- Proof 1: Ortografía, fidelidad, integridad, corrección, números y cifras, puntuación – este proceso normalmente lo realizará una persona manualmente o bien implementando una QA que realizará ella;
- Proof 2: postedición avanzada – lo realizará el traductor manualmente o con la asistencia de un software.
La propuesta de un nuevo sistema de QA (método de postedición avanzada) se resume en tres pasos:
SYNONYM RICH: en este proceso se controla que no existan más de 4 repeticiones de una misma palabra dentro de un mismo texto (o dentro de 1.000 palabras).
No deben aparecer una relación de más de 4/1000 de repetición para un vocablo determinado (excluyéndose los casos de palabras comunes, determinantes, artículos, preposiciones y conjunciones). Pensamos que es erróneo y contraproducente para el cliente la repetición de la misma palabra cientos o miles de veces. Si para una palabra determinada existen sinónimos, tanto el traductor como el lector pueden reconocer y establecer una relación de referencia.
Al margen de aspectos más técnicos de lingüística teórica, lo que asegura el sistema es:
* Un texto humano que los robots de los motores de búsqueda reconocen como humano y no procesado, mejorándose el posicionamiento de la empresa;
* Buenos resultados en textos con una mayor importancia de la redacción como presentaciones, informes, artículos, etc.;
* Mejor calidad y menos aburrimiento para el lector en la mayoría de los textos, con independencia de su categoría.
Programación: la programación se puede realizar excluyendo las palabras comunes (conjunciones, determinantes y artículos comunes), también es posible emplear un corpus para sacar listas de palabras infrecuentes (cuya repetición – además – se interpreta como «muletillas»: manifiestamente, por consiguiente, etc.), se puede realizar por la longitud de las palabras (por ejemplo, las esdrújulas serán menos comunes que las graves y agudas); por categoría gramatical; por derivación (sufijos: – ción, -izar, etc.).
WORD ORDER PLUS: Frente a una realidad de traducciones pasmosamente calcadas, el sistema Word Order Plus propone huir del calco del orden de elementos del texto original. Al menos un 50 % del texto traducido debe tener un orden de palabras que se diferencie del original. Por tanto, el programa deberá contrastar el orden de los elementos en la frase original y traducida para comprobar que no es calcada (se puede programar con listas y categorías – sustantivo / verbo / adjetivo y también alimentando al programa con un diccionario bilingüe o bien un glosario muy extenso en cuanto a volumen de entradas).
RE-WRITING PRO: Como extensión del proceso anterior, la fase final de re-writing busca una postedición avanzada sobre la base del proceso de Word Order Plus. En esta fase un 25 – 50 % de las frases han de reescribirse parcialmente y un 10 – 25 % totalmente. Esta fase se controla automáticamente viendo las postediciones realizadas en el texto destino (verificar que sí se han realizado estas postediciones).
EJEMPLOS DE FRASES QUE ERRÓNEAMENTE CORRIGE UN NUEVO Sistema de QA:
Como hemos dicho la QA mal programada puede corregir frases por su programación de base biunívoca y por su desconocimiento de las relaciones de referencia. La referencia es una operación esencial en todo texto en el que se va hilando una relación entre elementos que refieren o «apuntan hacia atrás» a un primer elemento.
Por ejemplo:
Compré un libro. Este era grande. LIBRO = ESTE. Este y el libro son lo mismo y «este» se refiere a «libro».
Es una explicación muy básica (y deficiente) de la referencia pero basta para entender el ejemplo siguiente:
TEXTO TRADUCIDO (LA QA MARCA COMO ERROR LAS PALABRAS EN NEGRITA):
Compré un libro. Mi incunable era un volumen precioso. Abracé esta mi obra al pecho.
Libro = incunable = volumen = esta mi obra
La máquina no está programada para entender que son lo mismo y las marca como errores. Porque no está programada para entender la referencia (elemento esencial de cohesión de los textos). Tampoco está programada, siquiera, con listas de sinónimos.
Lo frustrante para el traductor / redactor es que un texto perfectamente redactado como el del ejemplo, con riqueza de palabras (no se repite la misma expresión machaconamente) pueda dar lugar a quejas de la máquina y la orden de cambiar el texto según lo que erróneamente indica dicha máquina.
Otros errores del Nuevo sistema de QA:
Otro caso concreto de error: palabras polivalentes SOURCE – TARGET
Pensemos en el caso de una palabra como EQUITY. Tiene, al menos, 8 posibles traducciones al español (activos, patrimonio, fondos propios, capital, etc.). A la vez, en el par inverso (la QA también realiza una comprobación inversa) nos encontramos con casos como PATRIMONIO (singular) y PATRIMONIOS (plural) que equivalen (ambas) a «equity».
Por ejemplo:
The client’s equity // The clients’ equity = El patrimonio del cliente / Los patrimonios del cliente //// Los patrimonios de los clientes / El patrimonio de los clientes
En estos casos nos podemos encontrar de todo en la QA: incluso que nos digan que una palabra en singular la tenemos que poner – erróneamente – en plural.
Estas traducciones dependen en gran medida del contexto y pensamos que – de momento – es difícil de programar un conocimiento del contexto a este nivel.
Sin embargo, AL MENOS y COMO MÍNIMO la máquina tiene que ser conocedora de la operación de la referencia y estar alimentada con diccionarios de sinónimos para que, si bien igualmente podría indicar como posible error las diferencias que encuentre en las traducciones de palabras como «equity» y «patrimonio» al menos no sea insuperable (se le fundan los circuitos) y admita cambios de un elemento por otro.
En el sistema que yo propongo, la propia máquina incluso tendría un menú de drop-down para permitir la selección de sinónimos de una palabra y así no repetir lo mismo (algo similar a una función de auto-suggest).
EJEMPLO DE QA CON MENÚ DESPLEGABLE DE SUGERENCIAS DE SINÓNIMOS:
En el caso de un texto que incumpliera los parámetros de repetición de palabras en un mismo texto, sería la propia QA la que sugeriría reemplazar esas palabras por sinónimos ya que su función debe ser sugerir mejoras del texto.
Menú desplegable de sinónimos para mejorar la calidad de la redacción de los textos.
Nuevo sistema de QA: EXCLUSIONES Y REFLEXIÓN:
De este nuevo sistema de QA se excluiría – seguramente – textos muy repetitivos como los manuales de instrucciones. No olvidemos que la base de las actuales CAT y las QAs (que revisan sobre esas CAT y trabajan en conjunción con las mismas) son manuales de instrucciones de automóviles. Fue la industria del automóvil norteamericana donde surgieron los primeros análisis de calidad en la traducción con plantillas en las que se analizaban tipos de errores.
Sin embargo, en estos tipos de textos (aunque también se pueden beneficiar y se pueden mejorar) no es muy relevante la redacción muy variada ni rica en expresiones. Por eso el nuevo sistema de QA actual es deficiente como modelo: porque parte de análisis que se realizaron para la industria automovilística y una serie de manuales extraordinariamente repetitivos y donde era esencial seguir a toda costa un glosario lo que no ocurre hoy en día en la mayoría de los textos que traducimos para la web, para revistas, textos jurídicos diversos, etc.
Como se ve en este pantallazo de SAE J2450 (base de los estándares posteriores) los términos son muy agresivos, como «violates a glossary» (ni que un glosario se pudiera violar), y las normas son extremadamente rígidas y vehementes (lo que se correspondería a la histeria e inflexibilidad actual en la aplicación de estas QAs).

Claro, pero esta QA se hizo para que no hubiera confusiones de gente que montaba piezas de coche y para que los traductores (que no tenían ni idea de lo que estaban traduciendo) no llamaran tornillo a lo que se llama clavo en otro lugar. Pero no se hizo para escribir informes empresariales, ni páginas web de empresas, ni muchísimos textos donde la creatividad y la redacción ingeniosa cobran protagonismo.
Nuevo sistema de QA, FUTURO DE LA QA:
Por tanto, mi propuesta es que el nuevo sistema de QA han de reprogramarse o que bien, por un proceso de competencia comercial en el mercado, han de surgir programas alternativos a las QAs existentes actualmente que señalen los errores y pobrezas de estas QA y propongan algo mejor que las sustituya (lo que, sin duda, tendrá que ocurrir tarde o temprano si se quiere avanzar de un nivel muy mediocre de corrección a una corrección que produzca o asista en la producción de textos excelentes y bien redactados).
Por último, la iniciativa podría venir también de los propios clientes que viendo sus malos resultados en motores de búsqueda o los textos que les están entregando exijan textos mejor redactados con postedición que asegure que sean menos repetitivos y con un orden de palabras más natural y menos rígido.
Y hasta aquí todo lo que debes saber sobre el Nuevo sistema de QA, si tienes alguna duda o puedes aportar nuevos errores que has detectado estaremos encantados de conocerlos, deja tu comentario con tu opinión ¿que opinas del Nuevo sistema de QA?
Traducciones juradas Madrid, Leon Hunter SL. Solicita presupuesto sin compromiso aquí.

- Cambios a tener en cuenta en la firma electrónica de las traducciones juradas – 12/06/2025
- Omisiones en las traducciones juradas – 03/12/2023
- Las direcciones en las traducciones juradas – 01/12/2023